
算法—9.二叉查找树
1.基本思想
我们将学习一种能够将链表插入的灵活性和有序数组查找的高效性结合起来的符号表实现。具体来说,就是使用每个结点含有两个链接(链表中每个结点只含有一个链接)的二叉查找树来高效地实现符号表,这也是计算机科学中最重要的算法之一。
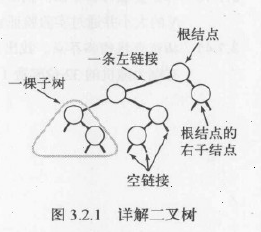
定义:一棵二叉查找树(BST)是一棵二叉树,其中每个结点都含有一个Comparable的键(以及相关联的值)且每个结点的键都大于其左子树中的任意结点的键而小于右子树的任意结点的键。
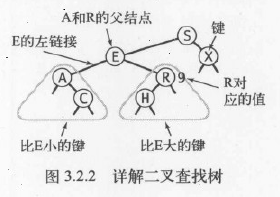
2.具体算法
/**
* 算法3.3 基于二叉查找树的符号表
* Created by huazhou on 2015/12/1.
*/
public class BST<Key extends Comparator<Key>, Value> {
private Node root; //二叉查找树的根结点
private class Node{
private Key key; //键
private Value val; //值
private Node left, right; //指向子树的链接
private int N; //以该结点为根的子树中的结点总数
public Node(Key key, Value val, int N){
this.key = key;
this.val = val;
this.N = N;
}
}
public int size(){
return size(root);
}
private int size(Node x){
if(x == null){
return 0;
}
else{
return x.N;
}
}
public Value get(Key key){
//见续1
}
public void put(Key key, Value val){
//见续1
}
}
左链接指向一棵由小于该结点的所有键组成的二叉查找树,右链接指向一棵由大于该结点的所有键组成的二叉查找树。变量N给出了以该结点为根的子树的结点总数。上面算法中实现的私有方法size()会将空链接的值当作0,这样我们就能保证以下公式对于二叉树中的任意结点x总是成立的。
size(x)=size(x.left)+size(x.right)+1
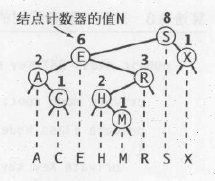
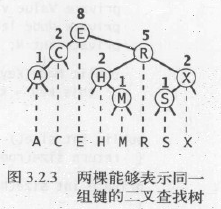
一棵二叉查找树代表了一组键(及其相应的值)的集合,而同一个集合可以用多棵不同的二叉查找树表示(如下图所示)。如果我们将一棵二叉查找树的所有键投影到一条直线上,保证一个结点的左子树中的键出现在它的左边,右子树中的键出现在它的右边,那么我们一定可以得到一条有序的键列。我们会利用二叉查找树的这种天生的灵活性,用多棵二叉查找树表示同一组有序的键来实现构建和使用二叉查找树的高效算法。
/**
*续1
*/
public Value get(Key key){
return get(root, key);
}
private Value get(Node x, Key key){
//在以x为根结点的子树中查找并返回key所对应的值
//如果找不到则返回null
if(x == null){
return null;
}
int cmp = key.compareTo(x.key);
if(cmp < 0){
return get(x.left, key);
}
else if(cmp > 0){
return get(x.right, key);
}
else{
return x.val;
}
}
public void put(Key key, Value val){
//查找key,找到则更新它的值,否则为它创建一个新的结点
root = put(root, key, val);
}
private Node put(Node x, Key key, Value val){
//如果key存在于以x为根结点的子树中则更新它的值;
//否则将以key和val为键值对的新结点插入到该子树中
if(x == null){
return new Node(key, val, 1);
}
int cmp = key.compareTo(x.key);
if(cmp < 0){
x.left = put(x.left, key, val);
}
else if(cmp > 0){
x.right = put(x.right, key, val);
}
else{
x.val = val;
}
x.N = size(x.left) + size(x.right) + 1;
return x;
}
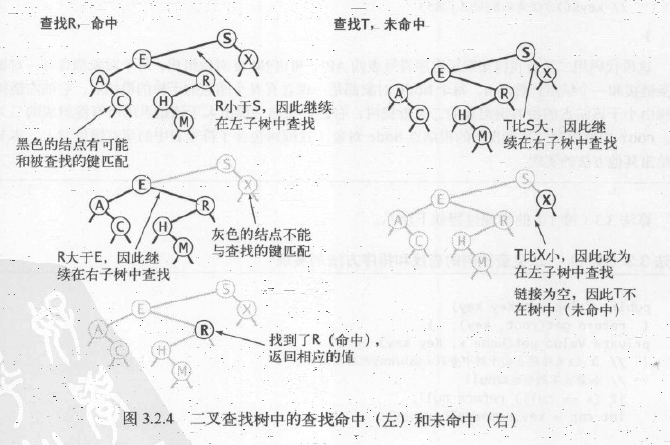
一般来说,在符号表中查找一个键可能得到两种结果。如果含有该键的结点存在于表中,我们的查找就命中了,然后返回相应的值。否则查找未命中(并返回null)。根据数据表示的递归结构我们马上就能得到,在二叉查找树中查找一个键的递归算法:如果树是空的,则查找未命中;如果被查找的键和根结点的键相等,查找命中,否则我们就(递归地)在适当的子树中继续查找。如果被查找的键较小就选择左子树,较大则选择右子树。算法续1中递归的get()方法完全实现了这段算法。它的第一个参数是一个结点(子树的根结点),第二个参数是被查找的键。代码会保证只有该结点所表示的子树才会含有和被查找的键相等的结点。和二分查找中每次迭代之后查找的区间就会减半一样,在二叉查找树中,随着我们不断向下查找,当前结点所表示的子树的大小也在减小(理想情况下是减半,但至少会有一个结点)。当找到一个含有被查找的键的结点(命中)或者当前子树变为空(未命中)时这个过程才会结束。从根结点开始,在每个结点中查找的进程都会递归地在它的一个子结点上展开,因此一次查找也就定义了树的一条路径。对于命中的查找,路径在含有被查找的键的结点处结束。对于未命中的查找,路径的终点是一个空链接,如下图所示。
算法续1中的查找代码几乎和二分查找的一样简单,这种简洁性是二叉查找树的重要特性之一。而二叉查找树的另一个更重要的特性就是插入的实现难度和查找差不多。当查找一个不存在于树中的结点并结束于一条空链接时,我们需要做的就是将链接指向一个含有被查找的键的新结点(见下图)。算法续1中递归的put()方法的实现逻辑和递归查找很相似:如果树是空的,就返回一个含有该键值对的新结点;如果被查找的键小于根结点的键,我们会继续在左子树中插入该键,否则在右子树中插入该键。
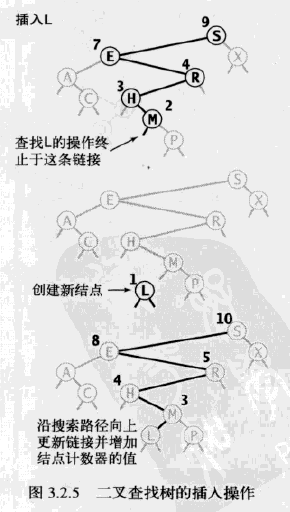
下图是对我们的标准索引用例轨迹的一份详细的研究,它向你展示了二叉树是如何生长的。新结点会连接到树底层的空链接上,树的其他部分则不会改变。例如,第一个被插入的键就是根结点,第二个被插入的键是根结点的两个子结点之一,以此类推。因为每个结点都含有两个链接,树会逐渐长大而不是萎缩。不仅如此,因为只有查找或者插入路径上的结点才会被访问,所以随着树的增长,被访问的结点数量占树的总结点数的比例也会不断的降低。


3.算法分析
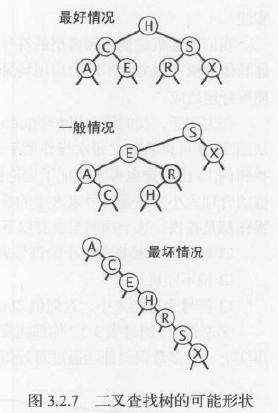
使用二叉查找树的算法的运行时间取决于树的形状,而树的形状又取决于键被插入的先后顺序。在最好的情况下,一棵含有N个结点的树是完全平衡的,每条空链接和根结点的距离都为~lgN。在最坏的情况下,搜索路径上可能有N个结点。如下图所示。但在一般情况下树的形状和最好情况更接近。
对于很多应用来说,下图所示的简单模型都是适用的:我们假设键的分布是(均匀)随机的,或者说它们的插入顺序是随机的。对这个模型的分析而言,二叉查找树和快速排序几乎就是“双胞胎”。树的根结点就是快速排序中的第一个切分元素(左侧的键都比它小,右侧的键都比它大),而这对于所有的子树同样适用,这和快速排序中对子数组的递归排序完全对应。这使我们能够分析得到二叉查找树的一些性质。

命题:在由N个随机键构造的二叉查找树中,查找命中平均所需的比较次数为~2lnN(约1.39lgN)。
证明:一次结束于给定结点的命中查找所需的比较次数为查找路径的深度加1。如果将树中的所有结点的深度加起来,我们就能够得到一棵树的内部路径长度。因此,在二叉查找树中的平均比较次数即为平均内部路径长度加1。令CN为由N个随机排序的不同键构造得到的二叉查找树的内部路径长度,则查找命中的平均成本为(1+CN/N)。我们有C0=C1=0,且对于N>1我们可以根据二叉查找树的递归结构直接得到一个归纳关系式:
CN=N-1+(C0+CN-1)/N+(C1+CN-2)/N+...+(CN-1+C0/)/N
其中N-1这一项表示根结点使得树中的所有N-1个非根结点的路径上都加了1。表达式的其他项代表了所有子树,它们的计算方法和大小为N的二叉查找树的方法相同。整理表达式后我们会发现,这个归纳公式和我们在之前为快速排序得到的公式几乎完全相同,因此我们同样可以得到CN~2NlnN。
命题:在由N个随机键构造的二叉查找树中插入操作和查找未命中平均所需的比较次数为~2lnN(约1.39lgN)。
证明:插入操作和查找未命中平均比查找命中需要一次额外的比较。这一点由归纳法不难得到。
4.总结
第一个命题说明在二叉查找树中查找随机键的成本比二分查找高约39%,第二个命题说明这些额外的成本是值得的,因为插入一个新键的成本是对数级别的——这是基于二分查找的有序数组所不具备的灵活性,因为它的插入操作所需访问数组的次数是线性级别的。和快速排序一样,比较次数的标准差很小,因此N越大这个公式越准确。
【源码下载】

